

✅ Sources d'entrainement des IA
Le fact-check
Historique
2 étapesPost Reçu
Publication
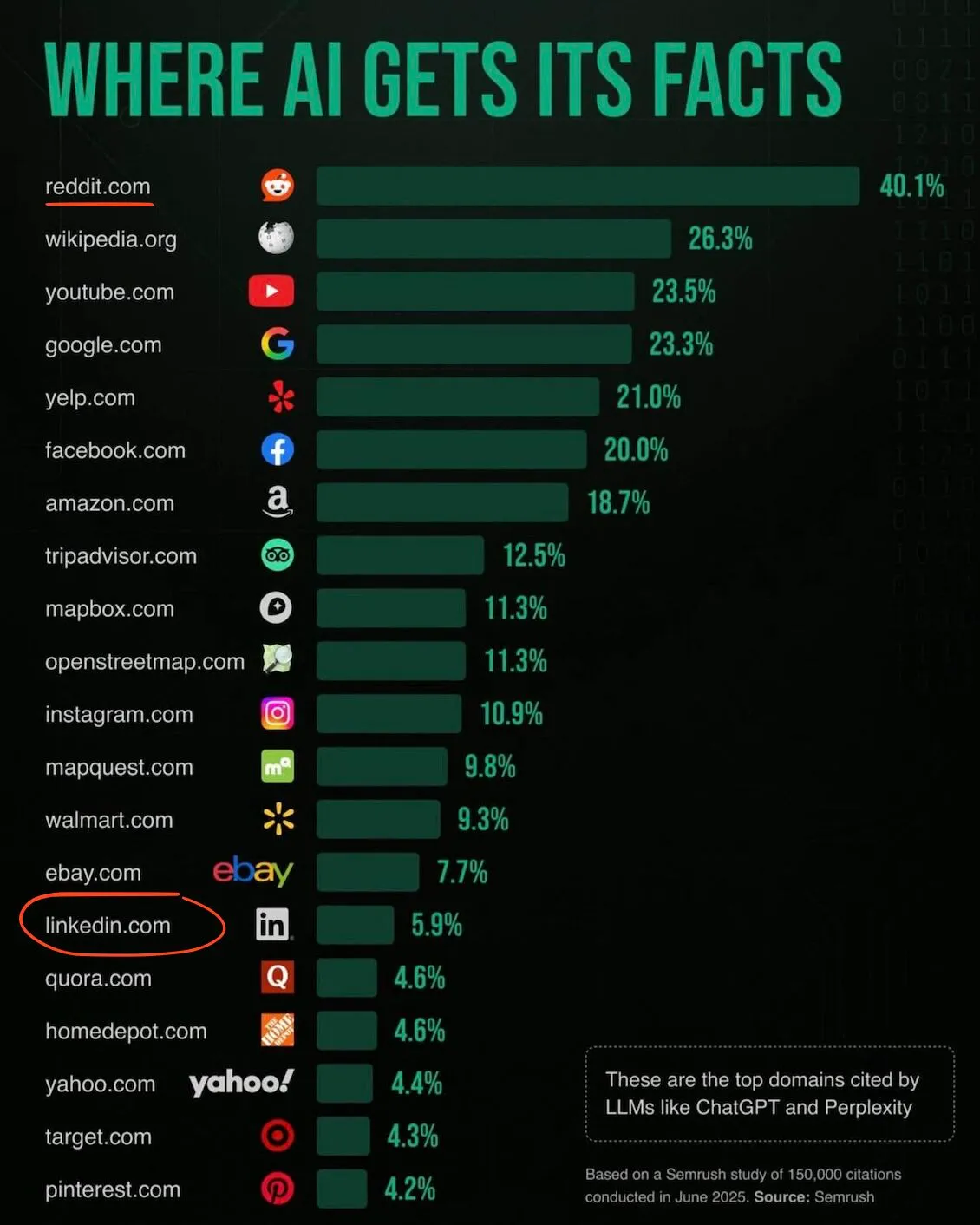
✅ On parle beaucoup du risque de « model collapse » : quand l'IA est entraînée principalement sur des données générées par d’autres IA, elle perd en diversité, ses réponses deviennent de moins en moins fiables et cohérentes. Des chercheurs l’ont démontré récemment : utiliser uniquement de la donnée synthétique appauvrit la qualité des modèles. https://cvc.li/Mxtln Avec Internet déjà saturé de textes produits par ChatGPT & co, la crainte est que les futures générations d’IA s’auto-intoxiquent. Mais des travaux montrent que mélanger données humaines et artificielles permet d’éviter cet effondrement. https://cvc.li/PXBCH Les entreprises en sont conscientes et investissent dans la curation et la collecte de contenu humain pour préserver la qualité des modèles. Il est courant que les LLM incluent des caractères invisibles dans les contenus générés pour justement distinguer human made vs robot made. https://cvc.li/SoDUc https://cvc.li/IsiOQ L’enjeu n’est pas la “fin de l’IA”, mais son alimentation. Dans le graphe, Reddit sort en premier. Normal, en 2024, il a vendu l'accès aux contenus de ses forums à Google pour entraîner son IA, en échange de 60 M$ annuel et un bon ranking dans les résultats de recherche... https://cvc.li/zdPTw
Vous avez une question, une remarque ou une suggestion ? Contactez-nous, nous vous répondrons au plus vite !
Nous contacter